Adapting Pretrained ViTs with
Convolution Injector for Visuo-Motor Control
ICML 2024
TL;DR: Add-on module which injects convolutions into pretrained ViTs for Visuo-motor Control
Abstract
Vision Transformers (ViT), when paired with large-scale pretraining, have shown remarkable performance across various computer vision tasks, primarily due to their weak inductive bias. However, while such weak inductive bias aids in pretraining scalability, this may hinder the effective adaptation of ViTs for visuo-motor control tasks as a result of the absence of control-centric inductive biases. Such absent inductive biases include spatial locality and translation equivariance bias which convolutions naturally offer. To this end, we introduce Convolution Injector (CoIn), an add-on module that injects convolutions which are rich in locality and equivariance biases into a pretrained ViT for effective adaptation in visuo-motor control. We evaluate CoIn with three distinct types of pretrained ViTs (CLIP, MVP, VC-1) across 12 varied control tasks within three separate domains (Adroit, MetaWorld, DMC), and demonstrate that CoIn consistently enhances control task performance across all experimented environments and models, validating the effectiveness of providing pretrained ViTs with control-centric biases.
Motivation
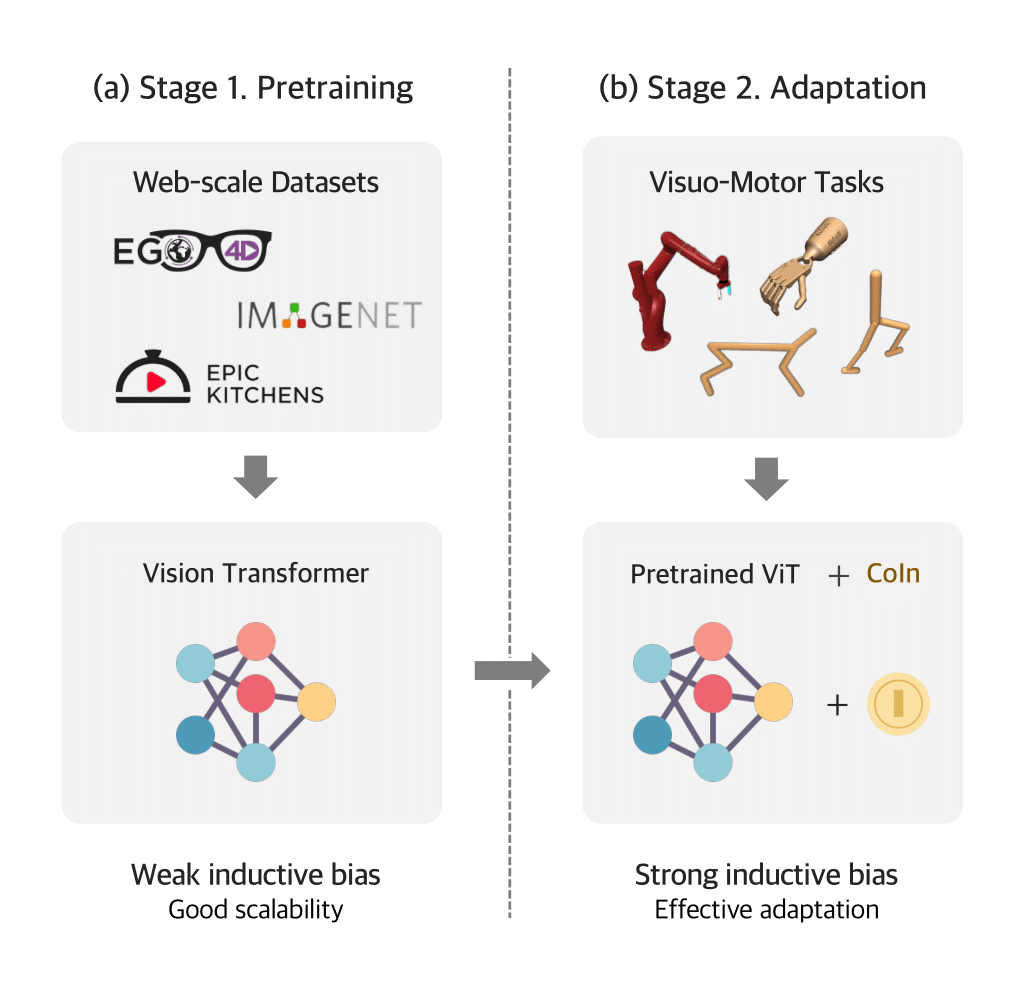
The advent of open-sourced, large-scale ViTs pretrained with extensive web-scale datasets provides generalized, ready-to-go visual representations. However, their weak inductive bias, though beneficial for scaling, impedes effective visuo-motor control. By integrating convolutional biases for spatial locality and translation equivariance, these limitations can be addressed.
Method: Convolution Injector (CoIn)
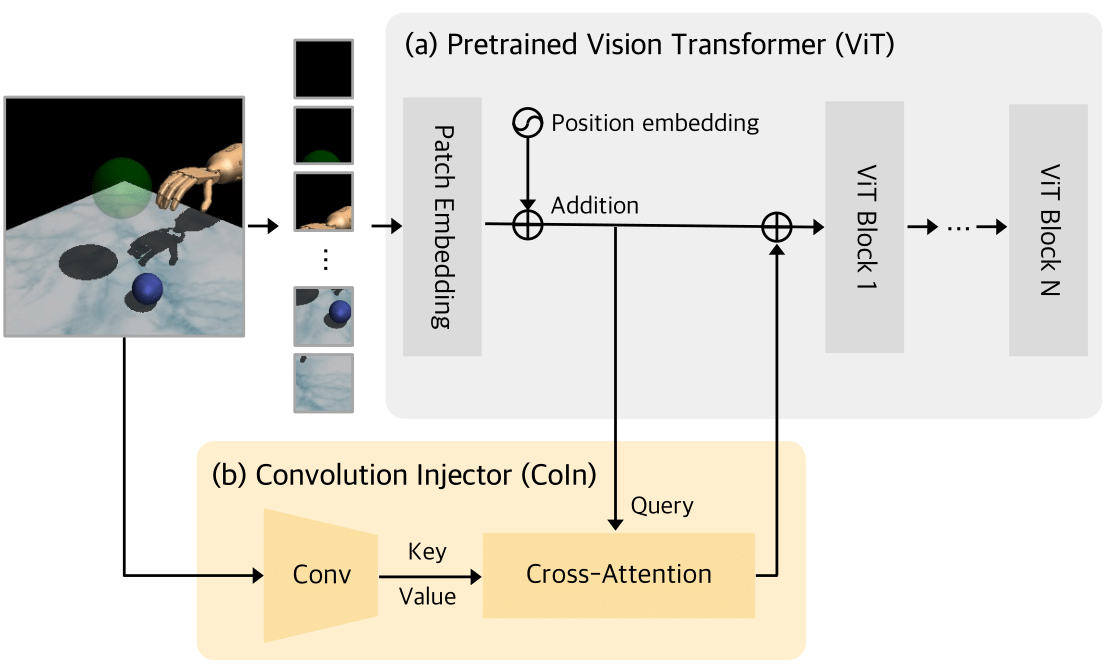
CoIn is a simple and lightweight add-on module (3.6% of additional parameters to a standard ViT-B/16) designed to exploit the strengths of pretrained ViTs while providing advantageous inductive biases essential for visual control tasks. While leaving the (a) ViT architecture untouched, (b) CoIn incorporates two key modules: a CNN encoder, which captures spatial locality and translation equivariance rich features from the input image, and a cross attention module, which introduces such biases into the ViT patch token embeddings. Notably, these enhancements are seamlessly integrated without any modification to the overall ViT architecture.
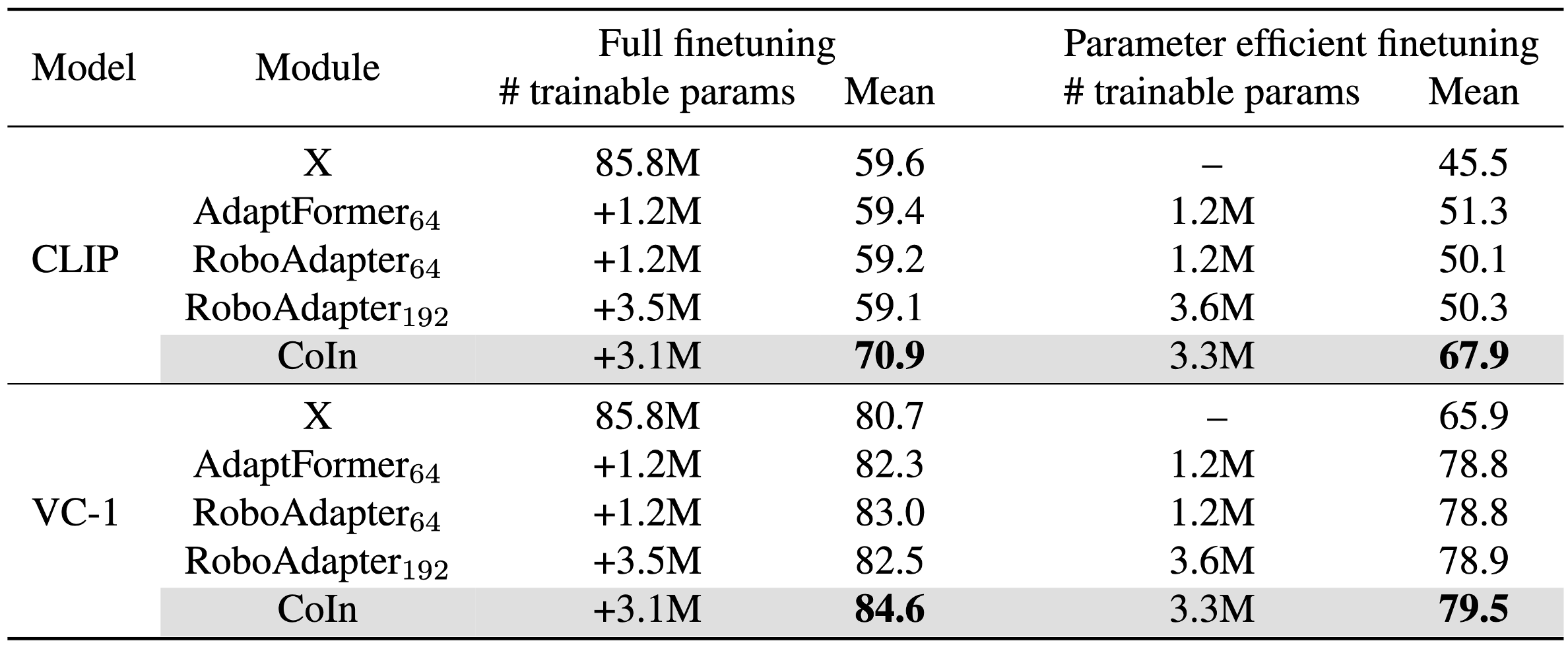
Experimental Results
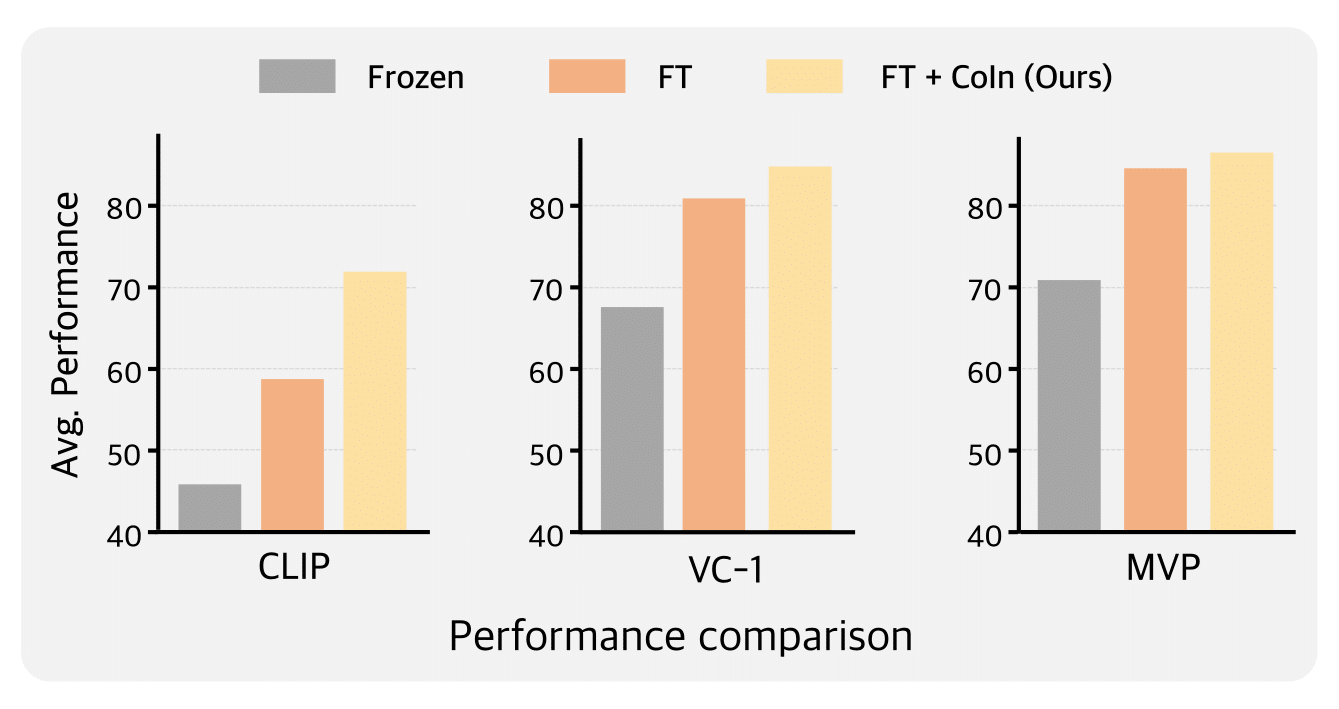
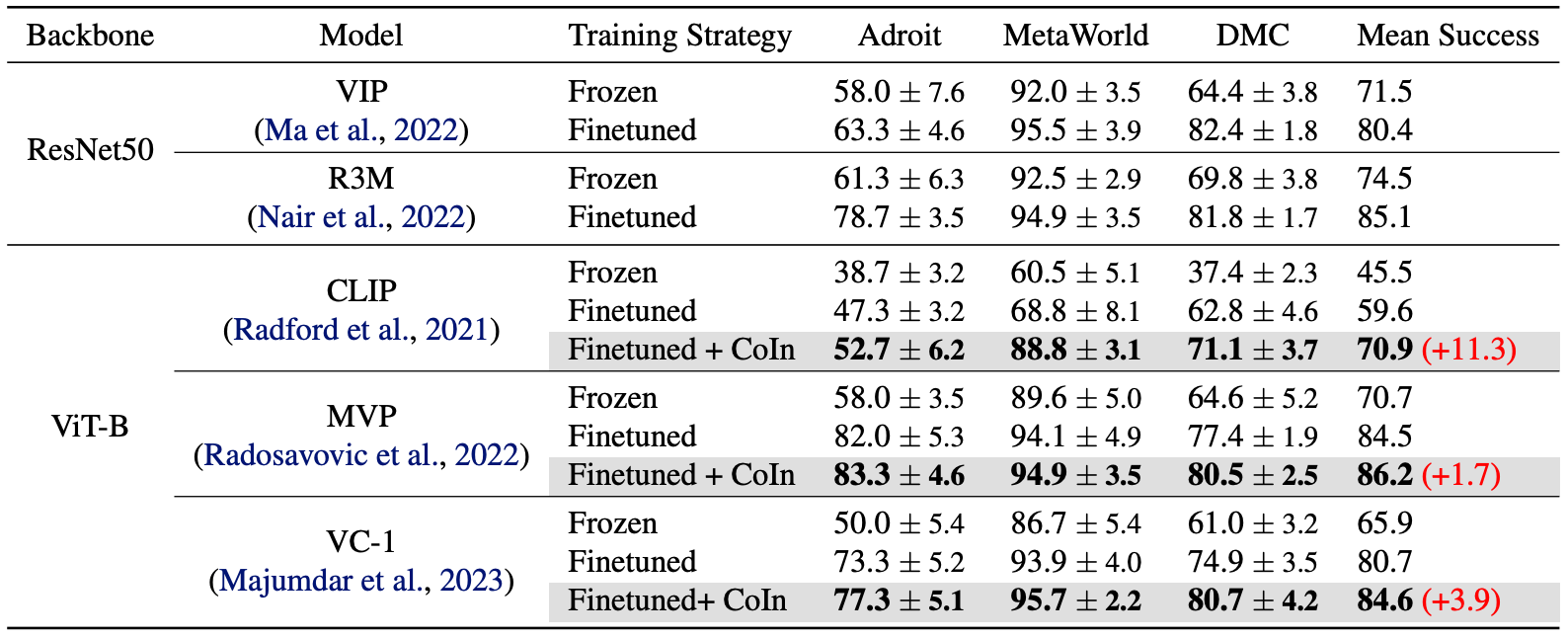
We finetuned various pretrained ViTs with CoIn on 12 control tasks across three domains (Adroit, MetaWorld, DMC). The integration of CoIn with various pretrained ViTs leads to notable performance enhancements across all pretrained ViT models and their associated control tasks.
In both the (Left) full finetuning and (Right) Peft finetuning (freezing the visual encoder and solely finetuning lightweight additional modules) scenarios against adapters, CoIn consistently outperformed other adapter baselines.
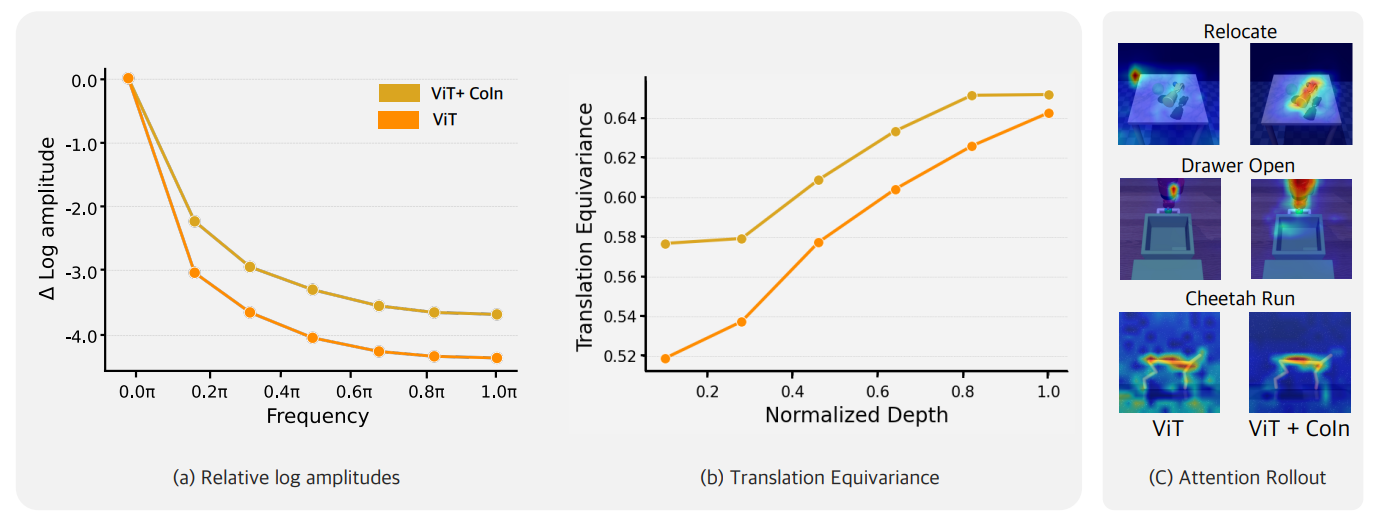
ViT + CoIn demonstrates following improvements: (a) capturing high-frequency signals, (b) improving translation equivariance, and (c) enhancing focus on crucial regions for visuo-motor control.
The website template was borrowed from Michaël Gharbi and Jon Barron.